Documentation Index
Fetch the complete documentation index at: https://docs.coloop.ai/llms.txt
Use this file to discover all available pages before exploring further.
As part of our processing step we also run models that correct common
transcript mistakes based on contextual information in the text — these are
not shown in the transcript.
- Once you’ve labelled all of the speakers in a transcript in the usual way and the document has been marked as ‘ready’
- You can go back and edit individual instances of speaker segments
There is currently a way to undo or go back without reuploading the audio.
Please make sure speaker labels are correct before clicking confirm
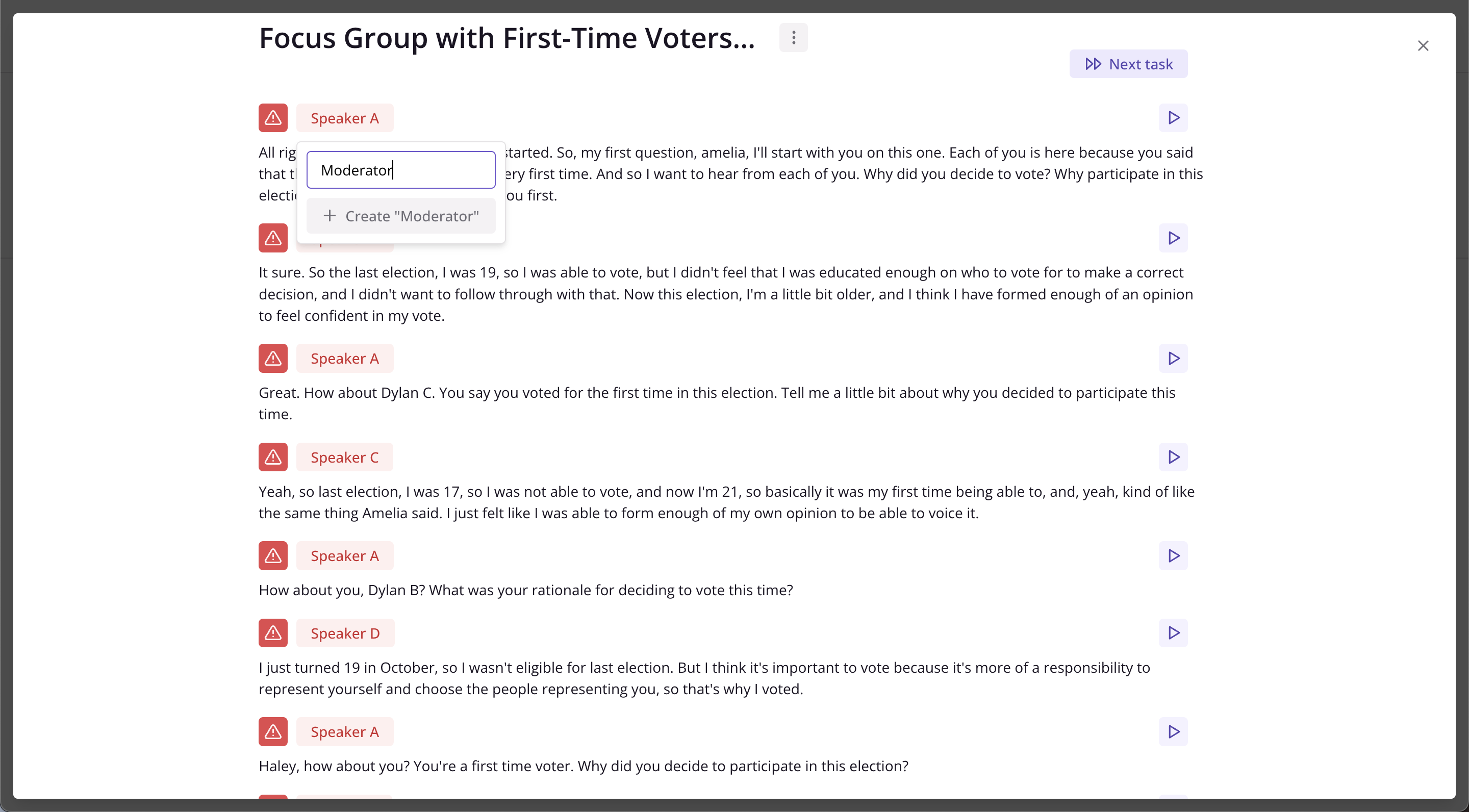 …Will change all instances of that particular speaker
…Will change all instances of that particular speaker
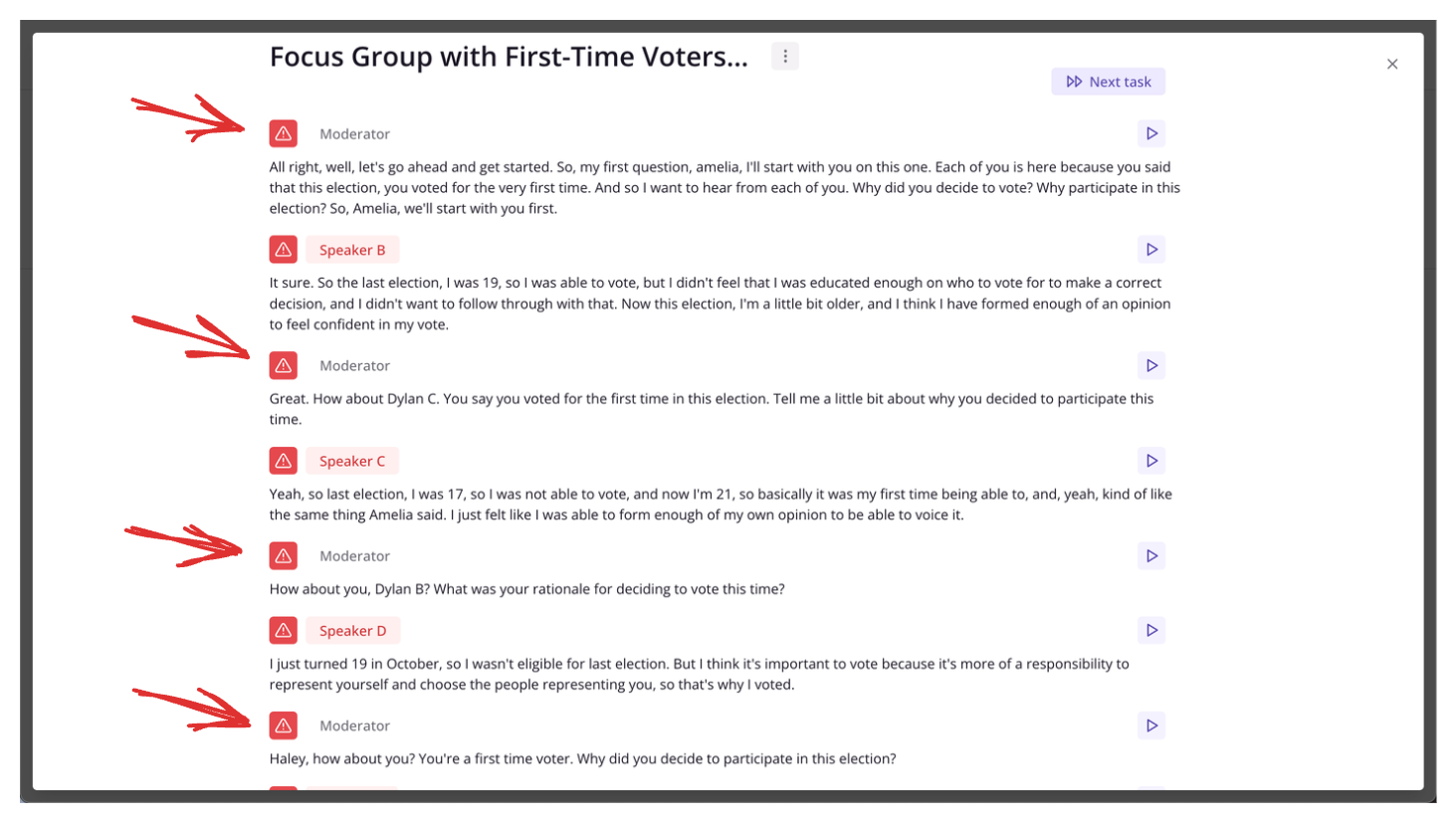 Once the speaker has been labelled, going back and editing it…
Once the speaker has been labelled, going back and editing it…
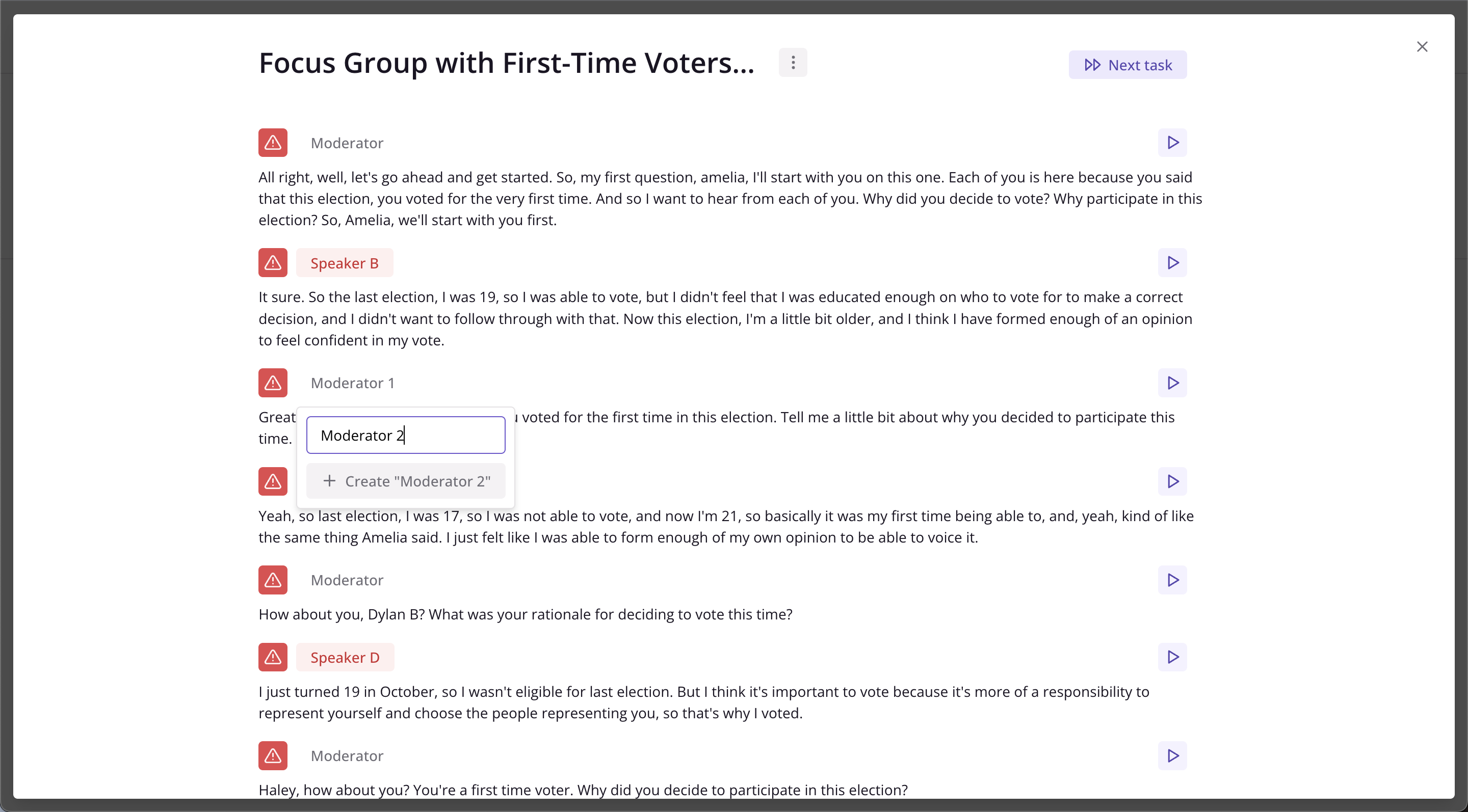 …Will only change that specific instance of the speaker
…Will only change that specific instance of the speaker
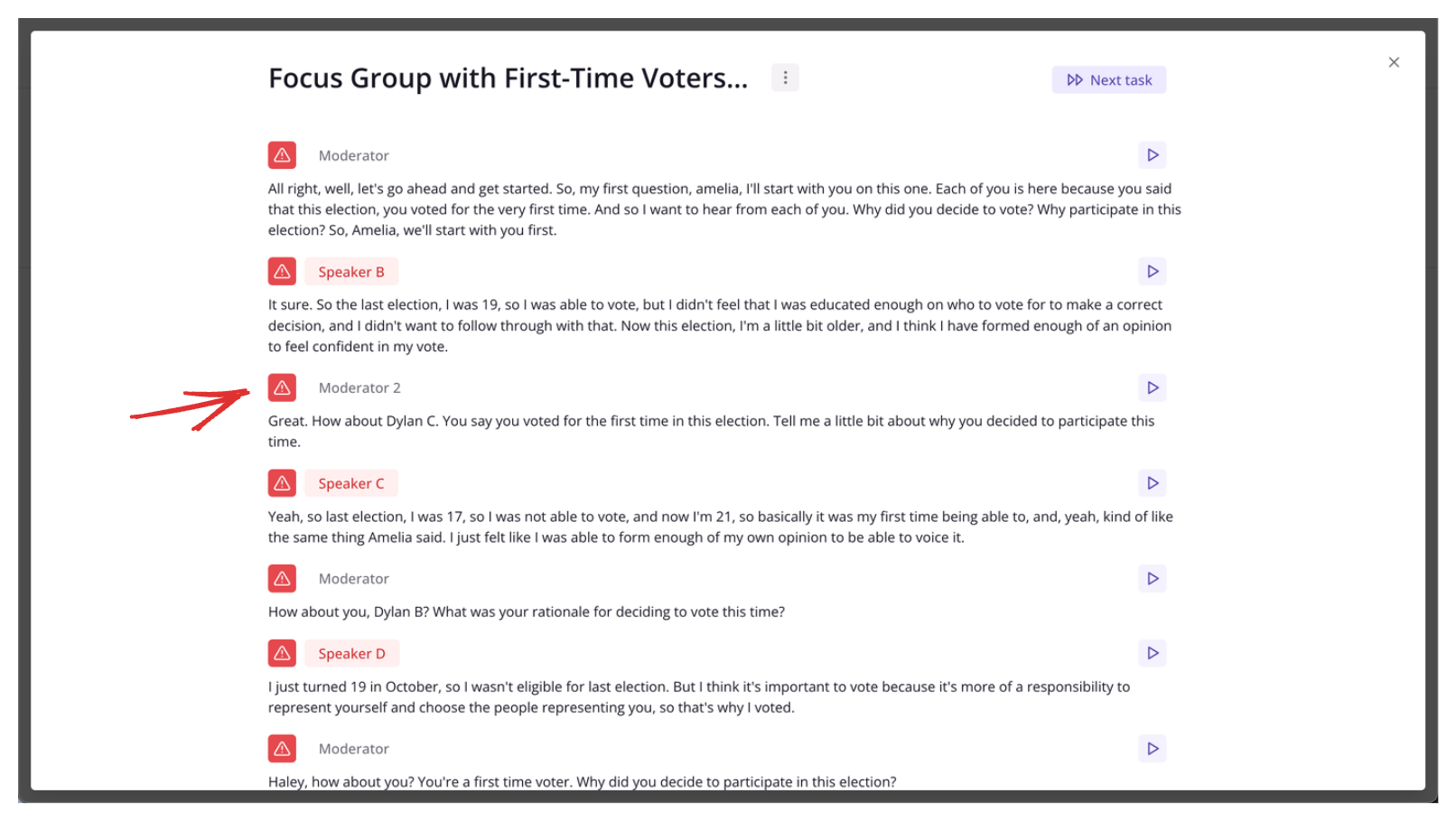 By doing this you can correct any incorrectly labelled segments you may come across.
By doing this you can correct any incorrectly labelled segments you may come across.